I'm about halfway through an effort to get test coverage up to 90-95% of lines and 100% of classes. I promise it'll get there eventually.
But in the mean time, I was playing with an improvement to how attributes are associated to data points. I knew this was a significant source of inefficiency, but didn't quite expect this much.
Here are memory usage graphs for training a Pitch Accent Detection model on the Boston University Radio News Corpus -- about 22k data points and 136 features. The first one is on my MacBookPro Laptop with 4G RAM (and a lot of other nonsense running).
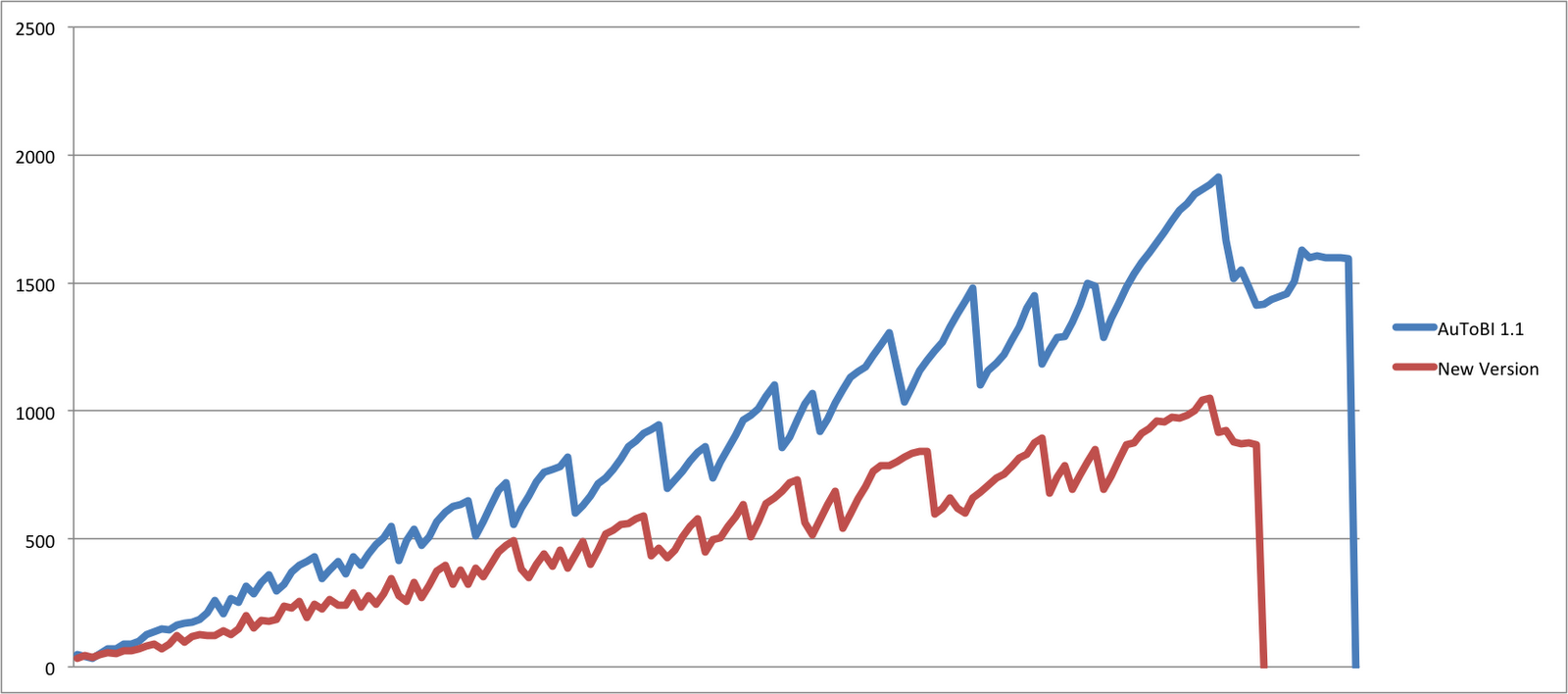
I figured I'd check on a compute server too, one of the Speech Lab @ Queens College's Quad Core Intel Xeon Processor E5450 (3.0GHz,2X6ML2,1333) with 4Gb RAM.

There are some other bugfixes in this version, but this is the big reason to upgrade.
The version 1.2 is available from github
git clone git@github.com:AndrewRosenberg/AuToBI.git
No comments:
Post a Comment